
Today’s valuations for AI and AI adjacent companies are primarily driven by the prospect of an autonomous and reproducible knowledge worker.
To give an illustrative example, in 2023, PwC reported gross revenue of £5.1bn and staff costs of £2.8bn. If the firm halved its staff costs, its profit (remembering that there are costs outside staff) would double, and the amount available to distribute to the partners would have been £2m each (rather than £900k).
The gap between AI as it exists and as it would need to be to achieve these savings is usually characterized as a model complexity and processing power deficit. This is demonstrably untrue and a source of an incredible amount of waste in terms of computing power and research time.
For AI to create the cost savings that it could at professional services firms, it must be highly specialized in its approach and implementation. A reliance on generalist chatbots will not cut it.
This was necessary with the internet: the technology was brilliant, but the value (as Google and Microsoft proved) was in the automation or digitization of specific tasks (email, information retrieval and search, etc.).
Tom Davenport and Maryam Alavi in a 2023 HBR article, talk about how firms are currently using AI to “inform their customer-facing employees and product/service recommendations” and “capture employees’ knowledge before they depart the organization” before making the point that:
These objectives were also present during the heyday of the “knowledge management” movement in the 1990s and early 2000s, but most companies found the technology of the time inadequate for the task.
The issue then, as now, was not inadequate technology: the issue was a clear demarcation of the role that the technology was expected to perform (and then the development of technology for those roles).
This raises three important questions that every firm needs to answer as a part of its AI deployment strategy:
- What are the specific tasks that we want an AI agent to be able to perform in a firm?
- What knowledge and skills are necessary to perform those tasks, and what are the outputs that the agent needs to deliver?
- How are the people currently performing those tasks recruited and trained to do them?
1. What are the specific tasks that we want an AI agent to be able to perform in a firm?
In his seminal Managing the Professional Service Firm, David Maister gives us the “Grinder, Minder, Finder” hierarchy for firms.
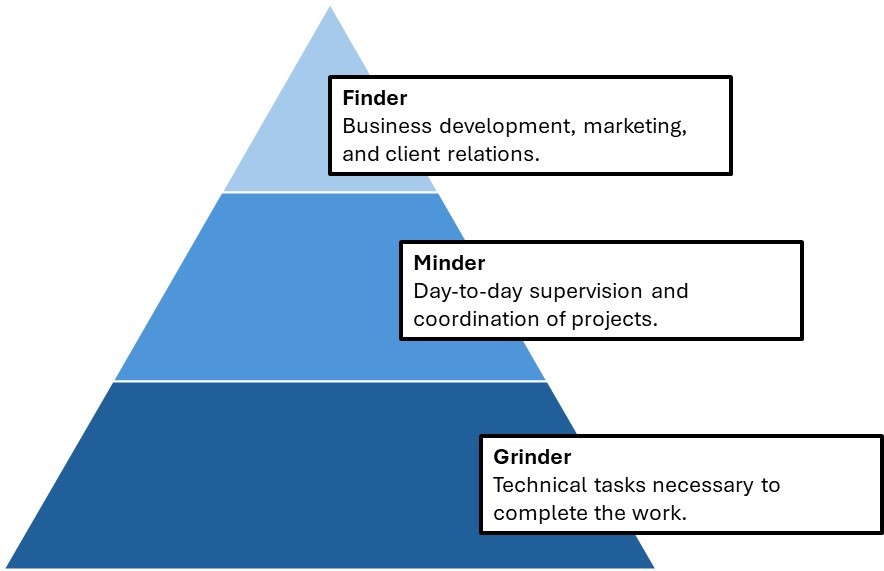
We want an AI agent to be able to perform as many of the tasks that “Grinders” are employed to do as possible.
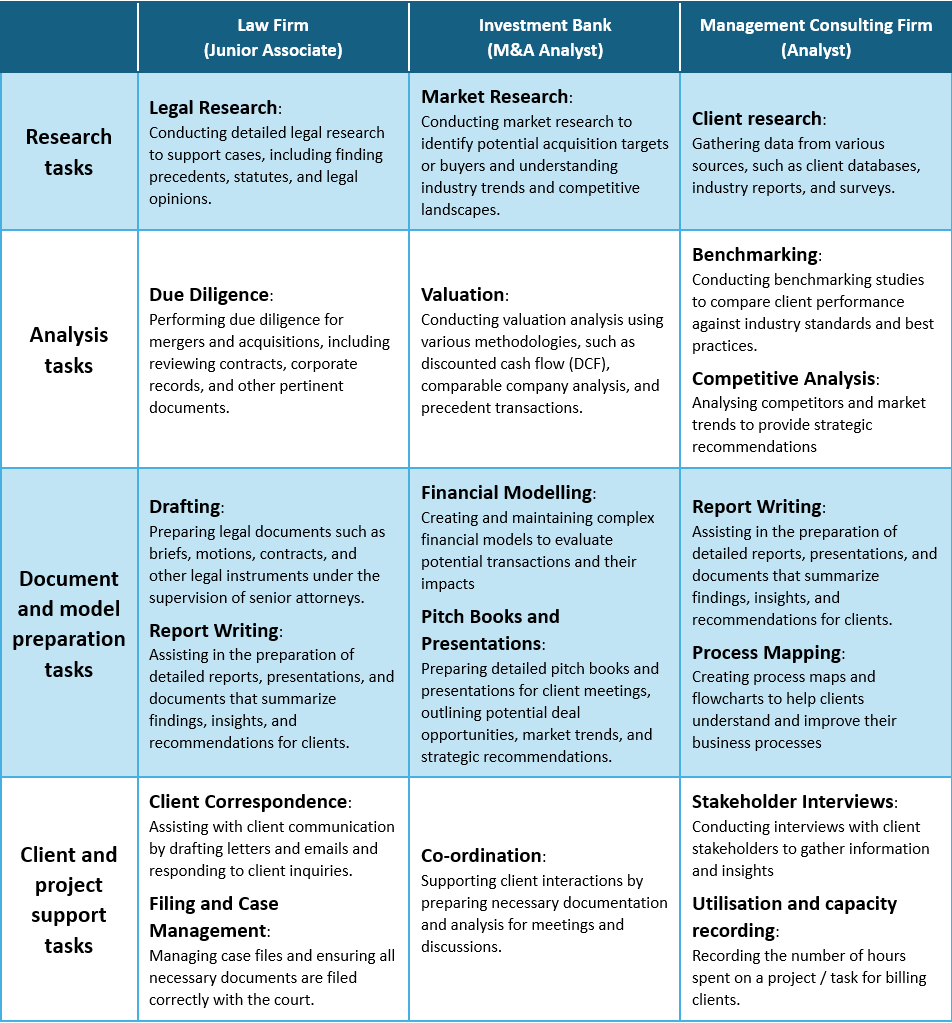
2. What knowledge and skills are necessary to perform those tasks, and what are the outputs that the agent needs to deliver?
If we keep the task groupings above, the skills and outputs that a firm will want from a “Grinder” AI agent are the following:
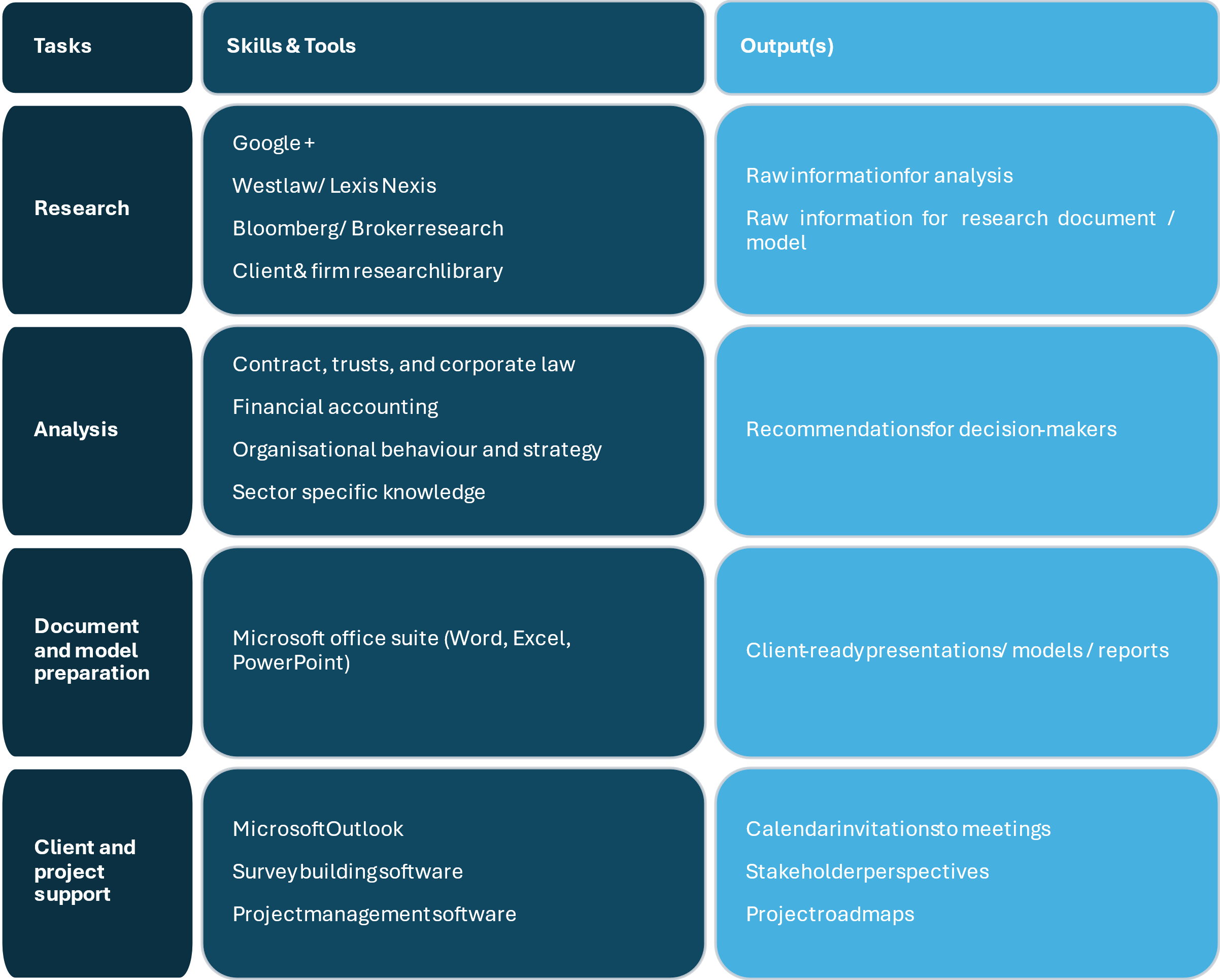
3. How are the people currently performing those tasks recruited and trained to do them?
The final question presents an important point with regards to the work that “grinders” are (or an AI agent would be) expected to do.
Professional services firms do not recruit entry level “grinders” on the basis of their ability to perform their entry-level role: they recruit them on the basis of their potential to one day become the “Finders” that will bring new clients (and revenue) into the company at 수원op.
As a result, most law firms, investment banks, and management consultancies will prefer an arts student from an elite institution over a law/accounting/business student from a less prestigious one (or an applicant without a degree but substantial evidence of the necessary skills). As Boris Groysberg and Sarah Mehta note in a 2022 Harvard Business School Case Study:
Most firms in America have come to use a college degree as a filter for hiring … studies had found that companies viewed degrees as a proxy for a range of skills.
Whether this is the correct way of building out the bottom of a firm’s pyramid is a separate question worthy of its own article, but this is the exact opposite of what we want in an AI agent.
Unfortunately, LLMs have been built on the “elite generalist” model. To demonstrate this, consider the fact that ChatGPT, Claude, and Gemini are in many ways ideal graduate scheme candidates:
- They are excellent at standardized tests.
- They are incredibly good at turning plain text requests into code (in any programming language).
- In a conversational interview setting, they can answer an infinite number of questions with much higher accuracy than most generalists.
- They exhibit a remarkable amount of confidence, even when making errors, but they will speedily reassess if a mistake is pointed out to them.
The difficulty is that LLMs lack the ability to learn organically like human analysts: building out interoperability between new tools and the LLM is much more complicated than running an onboarding/training session for analysts.
So, what should firms do?
The more logical approach for firms is to find, build, or white-label tools that do the specific tasks that they want to automate before using LLMs to “translate” instructions that come from the “Minders” in Maister’s framework into commands that the specialized tools can interpret and deliver.
It is worth highlighting the alternative to this view: eventually, LLMs will be able to take vague instructions, build the connections to the necessary tools, produce the needed output, and retain that knowledge for adjacent tasks. This is essentially a brute-force method.
A 2020 Paper from Thompson, Greenewald, Lee, and Manso warns against this approach. Their paper, titled ‘The computational limits of deep learning’ points out that even though a sufficiently large neural network will be able to operate as a universal function approximator (given a large enough model and training data set), there remains a tremendous obstacle in that:
“… deep learning’s prodigious appetite for computing power limits how far it can improve performance in its current form, particularly in an era when improvements in hardware performance are slowing … the growing computational burden of deep learning will soon be constraining for a range of applications, making the achievement of important benchmark milestones impossible if current trajectories hold”
Author Bio:
Sources cited:
Davenport, T., & Alavi, M. (2023, July 6). How to train generative AI using your company’s data. Harvard Business Review. https://hbr.org/2023/07/how-to-train-generative-ai-using-your-companys-data
Maister, D. H., & Maister, D. (2003). Managing the professional service firm (Paperback ed). Free Press [u.a.].
Skills-first hiring at IBM—Teaching note—Faculty & research—Harvard Business School. (n.d.). Retrieved 8 August 2024, from https://www.hbs.edu/faculty/Pages/item.aspx?num=65869
Thompson, N. C., Greenewald, K., Lee, K., & Manso, G. F. (2022). The computational limits of deep learning (arXiv:2007.05558). arXiv. https://doi.org/10.48550/arXiv.2007.05558

Read Dive is a leading technology blog focusing on different domains like Blockchain, AI, Chatbot, Fintech, Health Tech, Software Development and Testing. For guest blogging, please feel free to contact at readdive@gmail.com.



